- CAMEL: A powerful multi-agent framework that enables Retrieval-Augmented Generation and multi-agent role-playing scenarios, allowing for sophisticated AI-driven tasks.
- Chunkr: A powerful document processing API built for efficient and scalable data extraction and preparation, perfect for Retrieval-Augmented Generation (RAG) workflows and large language models (LLMs).
- Mistral AI: A series of high-performance LLMs.
Table of Content:
- 🧑🏻💻 Introduction
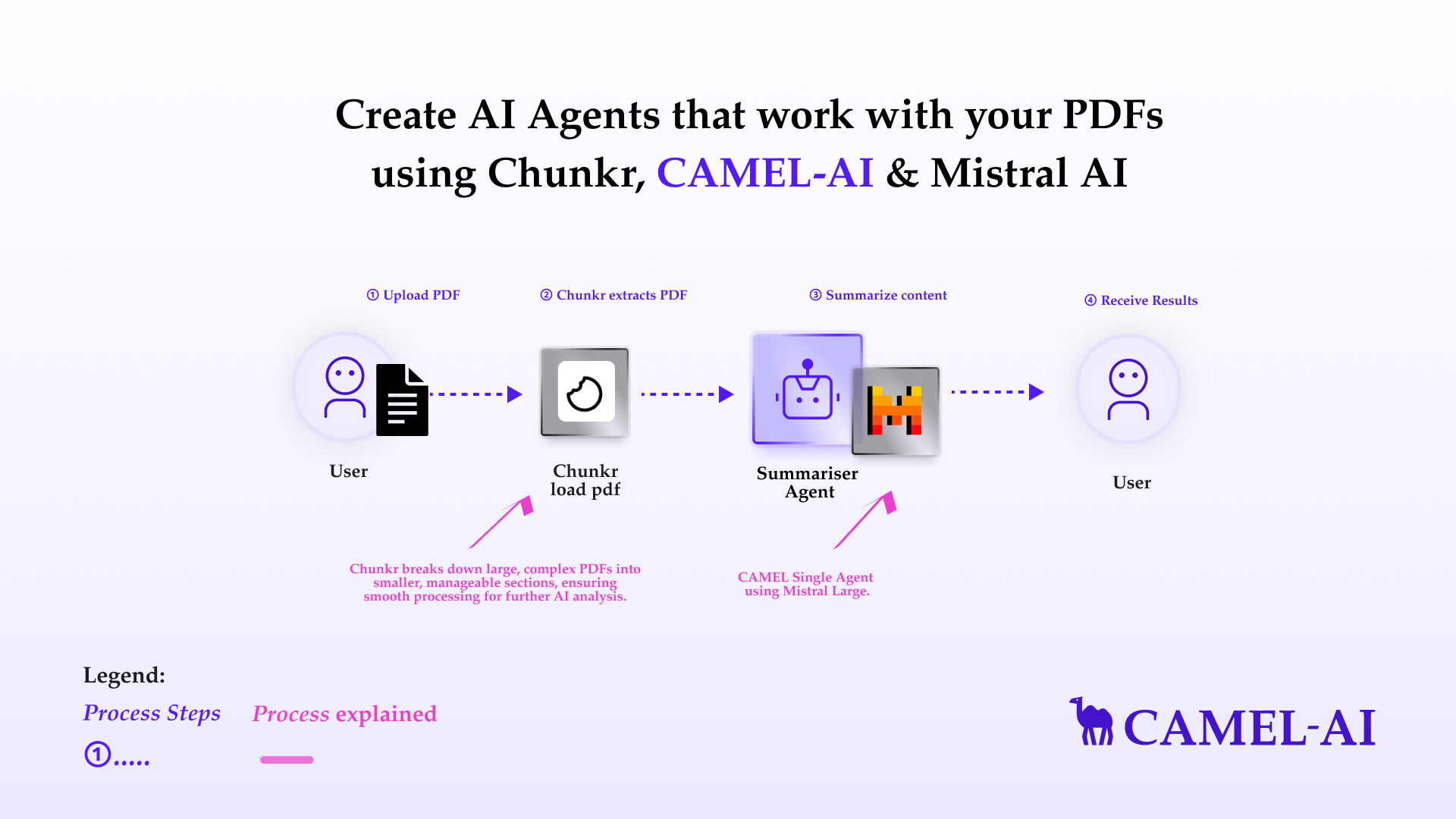
- ⚡️ Step-by-step Guide of Digesting PDFs with Chunkr
- 💫 Quick Demo with CAMEL Agent
- 🧑🏻💻 Conclusion


Introduction
Chunkr is a versatile API designed to revolutionize how documents are processed and made ready for advanced AI applications like RAG and LLMs. From extracting text to structuring complex layouts, Chunkr simplifies the workflow of transforming raw documents into actionable data.Key Features of Chunkr:
- Document Segmentation:
- Breaks down documents into coherent chunks using transformer-based models.
- Provides a logical flow of content, maintaining the context needed for efficient data analysis.
- Advanced OCR (Optical Character Recognition) Capabilities:
- Extracts text and bounding boxes from images or scanned PDFs using high-precision OCR.
- Makes content searchable, analyzable, and ready for integration into AI models.
- Semantic Layout Analysis:
- Detects and tags content elements like headers, paragraphs, tables, and figures.
- Converts document layouts into structured outputs like HTML and Markdown.
Why Use Chunkr?
- Optimized for AI: Simplifies preparing data for LLMs and other AI models.
- Multi-Format Compatibility: Processes PDFs, DOCX, PPTX, XLSX, and more.
- Scalable Deployment: Use locally for small projects or deploy at scale with Kubernetes. Also, it is open-source!
📦 Installation
First, install the CAMEL package with all its dependencies.⚡️ Step-by-step Guide of Digesting PDFs with Chunkr
Step 1: Set up your chunkr API key. If you don’t have a chunkr API key, you can obtain one by following these steps:- Create an account:
- Get your API key:
- Formatted Content: Text in structured formats like JSON, HTML, or Markdown.
- Semantic Tags: Identifies headers, paragraphs, tables, and other elements.
- Bounding Box Data: Spatial positions of text (x, y coordinates) for OCR-processed documents.
- Metadata: Information like page numbers, file type, and document properties.
💫 Quick Demo with CAMEL Agent
Here we choose Mistral model for our demo. If you’d like to explore different models or tools to suit your needs, feel free to visit the CAMEL documentation page, where you’ll find guides and tutorials. If you don’t have a Mistral API key, you can obtain one by following these steps:- Visit the Mistral Console (https://console.mistral.ai/)
- In the left panel, click on API keys under API section
- Choose your plan
🌟 Highlights
In conclusion, integrating Chunkr within CAMEL-AI revolutionizes the process of document data extraction and preparation, enhancing your capabilities for AI-driven applications. With Chunkr’s robust features like Segment, OCR, and Structure, you can seamlessly process complex documents into structured, machine-readable formats optimized for LLMs, directly feeding into CAMEL-AI’s multi-agent workflows. This integration not only simplifies data preparation but also empowers intelligent and accurate analytics. With these tools at your disposal, you’re equipped to transform raw document data into actionable insights, unlocking new possibilities in automation and AI-powered decision-making. Key tools utilized in this notebook include:- CAMEL: A powerful multi-agent framework that enables Retrieval-Augmented Generation and multi-agent role-playing scenarios, allowing for sophisticated AI-driven tasks.
- Chunkr: An advanced document processing API built for efficient and scalable data extraction and preparation, perfect for Retrieval-Augmented Generation (RAG) workflows and large language models (LLMs).
- 🐫 Creating Your First CAMEL Agent free Colab
- Graph RAG Cookbook free Colab
- 🧑⚖️ Create A Hackathon Judge Committee with Workforce free Colab
- 🔥 3 ways to ingest data from websites with Firecrawl & CAMEL free Colab
- 🦥 Agentic SFT Data Generation with CAMEL and Mistral Models, Fine-Tuned with Unsloth free Colab