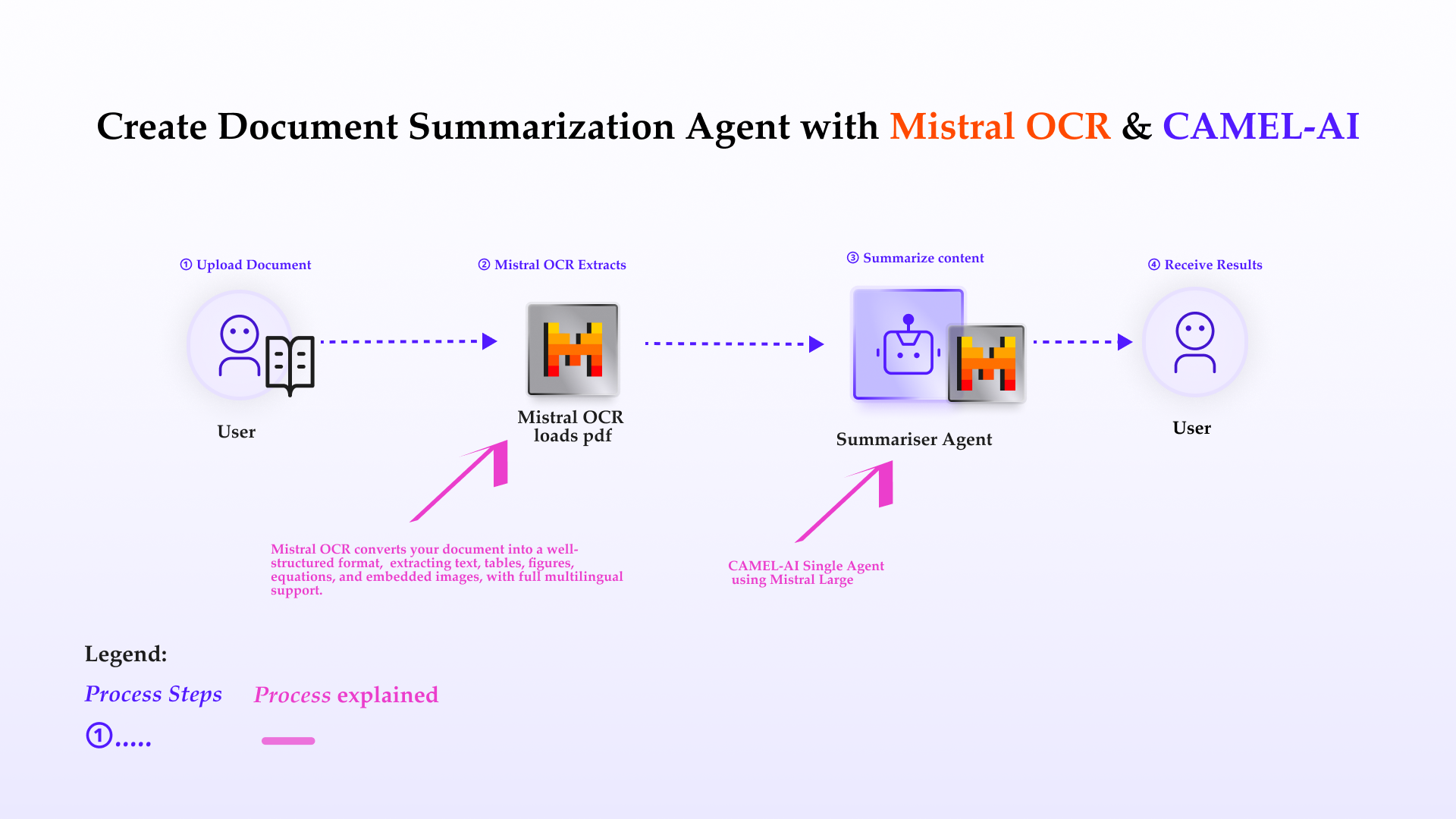
- Use the Mistral OCR API to convert scanned or image-based PDFs into structured Markdown
- Leverage a Mistral LLM agent within CAMEL to summarize and analyze the extracted content
- Build a seamless, end-to-end pipeline for retrieval-augmented generation (RAG), research, or business automation
Table of Contents
- 🧑🏻💻 Introduction
- ⚡️ Step-by-step Guide: Mistral OCR Extraction
- 💫 Quick Demo with Mistral Agent
- 🧑🏻💻 Conclusion


Introduction to Mistral OCR
Throughout history, advancements in information abstraction and retrieval have driven human progress—from hieroglyphs to digitization. Today, over 90% of organizational data lives in documents, often locked in complex layouts and multiple languages. Mistral OCR ushers in the next leap in document understanding: a multimodal API that comprehends every element—text, images, tables, equations—and outputs ordered, structured Markdown with embedded media references.Key Features of Mistral OCR:
-
State-of-the-art complex document understanding
- Extracts interleaved text, figures, tables, and mathematical expressions with high fidelity.
-
Natively multilingual & multimodal
- Parses scripts and fonts from across the globe, handling right-to-left layouts and non-Latin characters seamlessly.
-
Doc-as-prompt, structured output
- Returns ordered Markdown, embedding images and bounding-box metadata ready for RAG and downstream AI workflows.
-
Top-tier benchmarks & speed
- Outperforms leading OCR systems in accuracy—especially in math, tables, and multilingual tests—while delivering fast batch inference (∼2000 pages/min).
-
Scalable & flexible deployment
- Available via
mistral-ocr-lateston Mistral’s developer suite, cloud partners, and on-premises self-hosting for sensitive data.
- Available via
⚡️ Step-by-step Guide: Mistral OCR Loader
Step 1: Set up your Mistral API key If you don’t have a Mistral API key, you can obtain one by following these steps:- Create an account: Go to Mistral Console and sign up for an organization account.
- Get your API key: Once logged in, navigate to Organization → API Keys, generate a new key, copy it, and store it securely.
Step 4: Obtain OCR output from Mistral
Once the task completes, retrieve its output using the returnedtask.id.
The output of Mistral OCR is a structured object:
💫 Quick Demo with CAMEL Agent
Here we choose Mistral model for our demo. If you’d like to explore different models or tools to suit your needs, feel free to visit the CAMEL documentation page, where you’ll find guides and tutorials. If you don’t have a Mistral API key, you can obtain one by following these steps:- Visit the Mistral Console (https://console.mistral.ai/)
- In the left panel, click on API keys under API section
- Choose your plan
🧑🏻💻 Conclusion
In conclusion, integrating Mistral OCR within CAMEL-AI revolutionizes the process of document data extraction and preparation, enhancing your capabilities for AI-driven applications. With Mistral OCR’s robust features—state-of-the-art complex document understanding, natively multilingual & multimodal parsing, and doc-as-prompt structured Markdown output—you can seamlessly process complex PDFs and images into machine-readable formats optimized for LLMs, directly feeding into CAMEL-AI’s multi-agent workflows. This integration not only simplifies data preparation but also empowers intelligent and accurate analytics at scale. With these tools at your disposal, you’re equipped to transform raw document data into actionable insights, unlocking new possibilities in automation and AI-powered decision-making. That’s everything: Got questions about 🐫 CAMEL-AI? Join us on Discord! Whether you want to share feedback, explore the latest in multi-agent systems, get support, or connect with others on exciting projects, we’d love to have you in the community! 🤝 Check out some of our other work:- 🐫 Creating Your First CAMEL Agent free Colab
- Graph RAG Cookbook free Colab
- 🧑⚖️ Create A Hackathon Judge Committee with Workforce free Colab
- 🔥 3 ways to ingest data from websites with Firecrawl & CAMEL free Colab
- 🦥 Agentic SFT Data Generation with CAMEL and Mistral Models, Fine-Tuned with Unsloth free Colab