

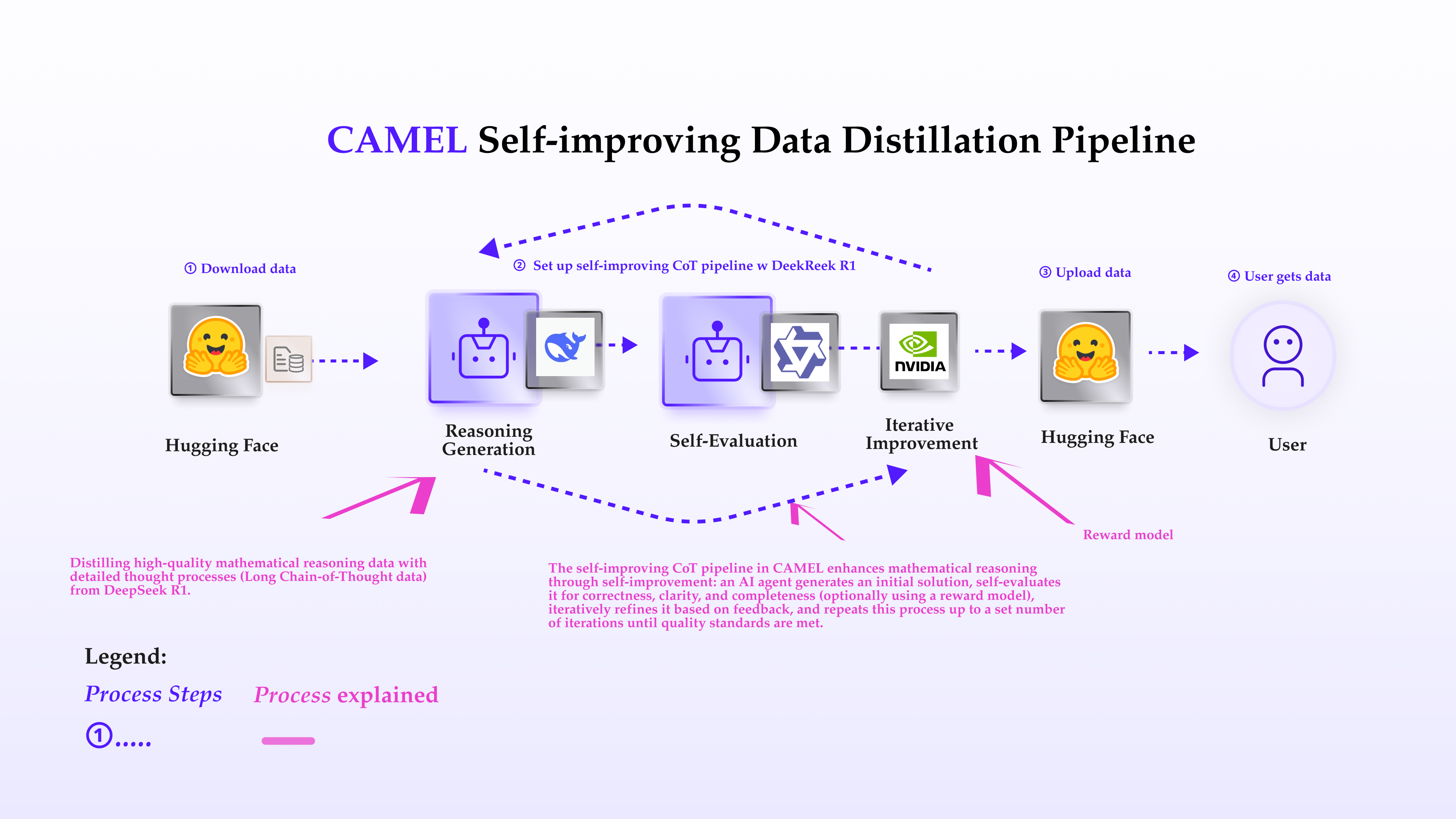
This notebook introduces CAMEL’s powerful self-improving data distillation pipeline, specifically designed to generate high-quality reasoning datasets. By incorporating self-improvement through iterative refinement, CAMEL enables the creation of long chain-of-thought (CoT) data with detailed reasoning processes. What Makes This Approach Special?
- Self-Improvement: The key feature of this pipeline is the ability to iteratively improve reasoning traces. By setting evaluation agent and a maximum number of iterations (e.g., max_iterations=2), the reasoning process is enhanced step by step, improve the quality of the solutions.
- Reasoning Trace Generation: CAMEL generates detailed reasoning for each mathematical problem. The generated traces are continuously evaluated, and based on feedback, they are refined and improved.
- 📚 AMC AIME STaR Dataset A dataset of 4K advanced mathematical problems and solutions, distilled with improvement history showing how the solution was iteratively refined. 🔗 Explore the Dataset
- 📚 AMC AIME Distilled Dataset A dataset of 4K advanced mathematical problems and solutions, distilled with clear step-by-step solutions. 🔗 Explore the Dataset
- 📚 GSM8K Distilled Dataset A dataset of 7K high quality linguistically diverse grade school math word problems and solutions, distilled with clear step-by-step solutions. 🔗 Explore the Dataset
📦 Installation
Firstly, we need to install the camel-ai package for datagen pipeline🔑 Setting Up API Keys
Let’s set theFIREWORKS_API_KEY or DEEPSEEK_API_KEY that will be used to distill the maths reasoning data with thought process.
⭐ NOTE: You could also use other model provider like Together AI, SilionFlow
📥 Download Dataset from Hugging Face and Convert to the Desired Format
Now, lets start to prepare the original maths data from Hugging Face ,which mainly have two important key: questions and answers. We will use GSM8K as example.🚀 Begin Distilling Mathematical Reasoning Data with Thought Process (Long CoT Data).
The Self-Improving CoT Pipeline is at the heart of CAMEL’s self-improving mechanism. It generates reasoning traces, evaluates them, and refines them iteratively. The pipeline executes the following core steps:- Initial Reasoning Generation: For each problem, an initial reasoning trace is created by the agent.
- Self-Evaluation: The agent evaluates the trace for correctness, clarity, and completeness. We also support evaluation with reward model
- Iterative Improvement: Based on the evaluation feedback, the reasoning trace is iteratively improved, ensuring enhanced logic and clarity with each iteration.
📤 Upload the Data to Hugging Face
After we’ve distilled the desired data, let’s upload it to Hugging Face and share it with more people! Define the dataset upload pipeline, including steps like creating records, generating a dataset card, and other necessary tasks.🔑 Config Access Token of Hugging Face and Upload the Data
You can go to here to get API Key from Hugging Face, also make sure you have opened the write access to repository.
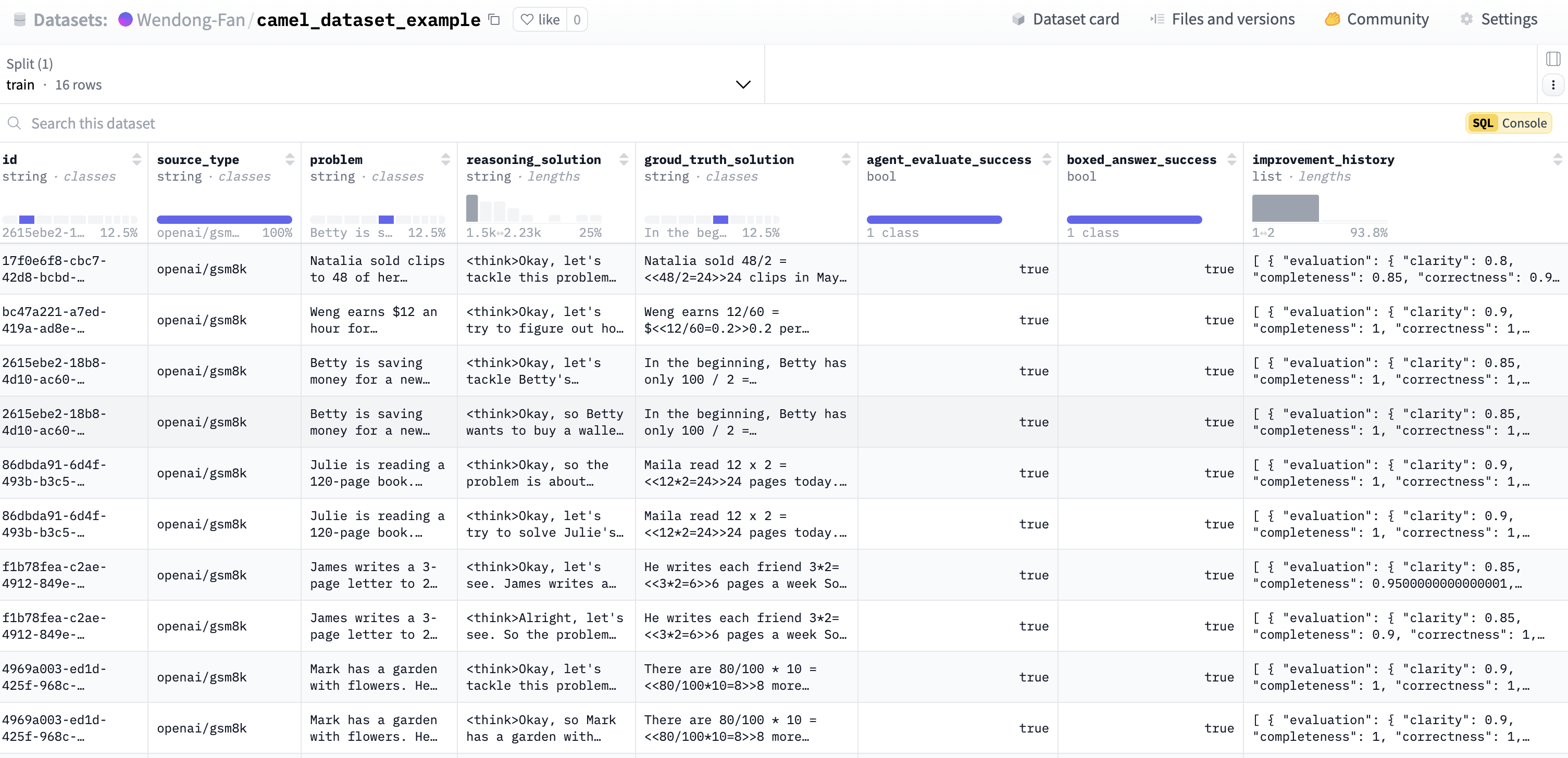
📊 Final Uploaded Data Preview
🌟 Highlights
The Self-Improving CoT Pipeline is a cutting-edge tool for generating long chain-of-thought reasoning data. By leveraging multiple iterations of evaluation and improvement, the pipeline creates high-quality reasoning traces that are perfect for advanced problem-solving and educational purposes. While the computational cost is significant, the resulting high-quality output is invaluable for building high quality synthetic data for model training. That’s everything! If you have questions or need support, feel free to join us on Discord. Whether you want to share feedback, explore the latest in multi-agent systems, or connect with others, we’d love to have you in the community! 🤝 That’s everything: Got questions about 🐫 CAMEL-AI? Join us on Discord! Whether you want to share feedback, explore the latest in multi-agent systems, get support, or connect with others on exciting projects, we’d love to have you in the community! 🤝 Check out some of our other work:- 🐫 Creating Your First CAMEL Agent free Colab
- Graph RAG Cookbook free Colab
- 🧑⚖️ Create A Hackathon Judge Committee with Workforce free Colab
- 🔥 3 ways to ingest data from websites with Firecrawl & CAMEL free Colab
- 🦥 Agentic SFT Data Generation with CAMEL and Mistral Models, Fine-Tuned with Unsloth free Colab