Deep Dive into CAMEL’s Practices for Self-Improving CoT Generation 🚀
The field of AI is rapidly evolving, with reasoning models playing a crucial role in enhancing the problem-solving capabilities of large language models (LLMs). Recent developments, such as DeepSeek’s R1 and OpenAI’s o3-mini, demonstrate the industry’s commitment to advancing reasoning through innovative approaches. DeepSeek’s R1 model, introduced in January 2025, has shown remarkable proficiency in tasks that require complex reasoning and code generation. Its exceptional performance in areas like mathematics, science, and programming is particularly noteworthy. By distilling Chain-of-Thought (CoT) data from reasoning models, we can generate high-quality reasoning traces that are more accurate in solving complex problems. These generated data can be used to further fine-tune another LLM with less parameters, thereby enhancing its reasoning ability. CAMEL developed an approach leverages iterative refinement, self-assessment, and efficient batch processing to enable the continuous improvement of reasoning traces. In this blog, we will delve into how CAMEL implements its self-improving CoT pipeline.1. Overview of the End-to-End Pipeline 🔍
1.1 Why an Iterative CoT Pipeline?
One-time CoT generation often leads to incomplete or suboptimal solutions. CAMEL addresses this challenge by employing a multi-step, iterative approach:- Generate an initial reasoning trace.
- Evaluate the trace through either a dedicated evaluation agent or a specialized reward model.
- Refine the trace based on the feedback provided.
1.2 Core Components
The self-improving pipeline consists of three key components:reason_agent: This agent is responsible for generating or improving reasoning traces.evaluate_agent: An optional agent that evaluates the quality of the reasoning trace. This can be replaced by a reward model if needed.reward_model: An optional model that provides numerical feedback on the trace, evaluating dimensions such as correctness, coherence, complexity, and verbosity.
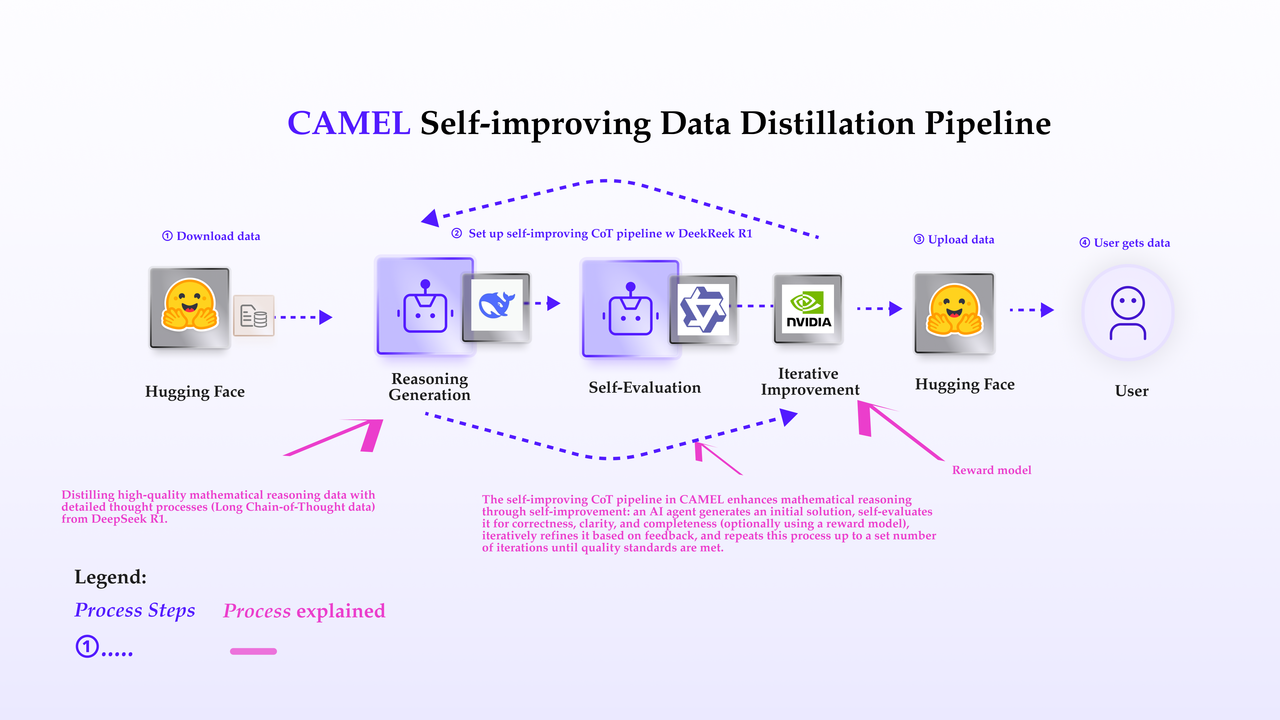
2. Generation of CoT Data: The Heart of the Pipeline 🤖
Generating CoT data is at the core of the pipeline. Below, we outline the process in detail.2.1 Initial Trace Generation 🐣
The first step in the process is the generation of an initial reasoning trace. Thereason_agent plays a central role here, creating a coherent and logical explanation of how to solve a given problem. The agent breaks down the problem into smaller steps, illustrating the thought process at each stage. We also support the use of non-reasoning LLMs to generate traces through prompt engineering.
The generation could also guided by few-shot examples, which provide context and help the agent understand the desired reasoning style. Here’s how this is accomplished:
- Input: The problem statement is provided to the
reason_agent, we can optionally provide the ground truth to guide the reasoning process. - Output: The agent generates a sequence of reasoning content.
2.2 Evaluation of the Initial Trace 📒
Once the reasoning trace is generated, it is evaluated for its quality. This evaluation serves two purposes:- Detecting weaknesses: The evaluation identifies areas where the reasoning trace could be further improved.
- Providing feedback: The evaluation produces feedback that guides the agent in refining the reasoning trace. This feedback can come from either the
evaluate_agentor areward_model.
2.2.1 Agent-Based Evaluation
If anevaluate_agent is available, it examines the reasoning trace for:
- Correctness: Does the trace logically solve the problem?
- Clarity: Is the reasoning easy to follow and well-structured?
- Completeness: Are all necessary steps included in the reasoning?
2.2.2 Reward Model Evaluation
Alternatively, the pipeline supports using a reward model to evaluate the trace. The reward model outputs scores based on predefined dimensions such as correctness, coherence, complexity, and verbosity.2.3 Iterative Refinement: The Self-Improving Cycle 🔁
The key to CAMEL’s success in CoT generation is its self-improving loop. After the initial trace is generated and evaluated, the model refines the trace based on the evaluation feedback. This process is repeated in a loop.How does this iterative refinement work?
- Feedback Integration: The feedback from the evaluation phase is used to refine the reasoning. This could involve rewording unclear parts, adding missing steps, or adjusting the logic to make it more correct or complete.
-
Improvement through Reasoning: After receiving feedback, the
reason_agentis used again to generate an improved version of the reasoning trace. This trace incorporates the feedback provided, refining the earlier steps and enhancing the overall reasoning. - Re-evaluation: Once the trace is improved, the new version is evaluated again using the same process (either agent-based evaluation or reward model). This new trace is assessed against the same criteria to ensure the improvements have been made.
- Threshold Check: The iterative process continues until the desired quality thresholds are met or reached the maximum number of iterations.
3. Pipeline Setup in Code 💻
Below is a truncated version of our pipeline initialization. We encapsulate logic in a class calledSelfImprovingCoTPipeline:
4. Batch Processing & API Request Handling 📦
4.1 The Need for Batch Processing ⏰
Early on, we tried generating CoT reasoning for each problem one by one. This approach quickly revealed two major issues:- Time consumption: Sequential processing doesn’t scale to large problem sets.
- API request bottlenecks: Slowdowns or occasional disconnections occurred when handling numerous calls.
BatchProcessor to:
- Split the tasks into manageable batches.
- Dynamically adjust batch size (
batch_size) based on the success/failure rates and system resource usage (CPU/memory). - Retry on transient errors or API timeouts to maintain a stable flow.
4.2 Handling API Instability 🚨
Even with batching, API requests for LLMs can fail due to network fluctuations or remote server instability. We implemented aretry_on_error decorator:
5. Model Switching & Dynamic File Writing 📝
5.1 Flexible Model Scheduling 🕒
In CAMEL’s CoT pipeline, adding models to theChatAgent is useful for handling errors and ensuring smooth operation. This setup allows the system to switch between models as needed, maintaining reasoning continuity.
To add models to a ChatAgent, you can create instances of models and include them in the agent’s model list:
5.2 Real-Time JSON Updates 🔄
As soon as a problem’s results are ready, we lock the file (output_path) and update it in-place—rather than saving everything at the very end. This ensures data integrity if the process is interrupted partway through.
.tmp file then replace) prevents partial writes from corrupting the output file.
6. CAMEL’s Next Steps in CoT Data Generation 🚀
- Real-Time Monitoring Dashboard: Visualize throughput, error rates, running cost, data quality, etc. for smooth operational oversight.
- Performance Enhancements: Further improve performance and add more error handling to make the system more robust.
- Cutting-Edge Research Solutions: Integrate more cutting-edge research solutions for synthetic data generation.
- Rejection Sampling: Integrate rejection sampling method to the SelfImprovingCoT pipeline.
Conclusion 📚
CAMEL’s self-improving pipeline exemplifies a comprehensive approach to Chain-of-Thought data generation:- Flexible Evaluation: Utilizing agent-based or reward-model-based evaluation provides adaptable scoring and feedback loops.
- Continuous Improvement: Iterative refinement ensures each reasoning trace is enhanced until it meets the desired quality.
- Efficient Processing: Batched concurrency increases throughput while maintaining system balance.
- Robust Stability: Error-tolerant mechanisms with retries enhance system reliability.
- Consistent Output: Dynamic file writing ensures partial results are consistently preserved and valid.
Further Reading & Resources
- CAMEL GitHub: Explore our open-source projects on GitHub and give us a 🌟star.