

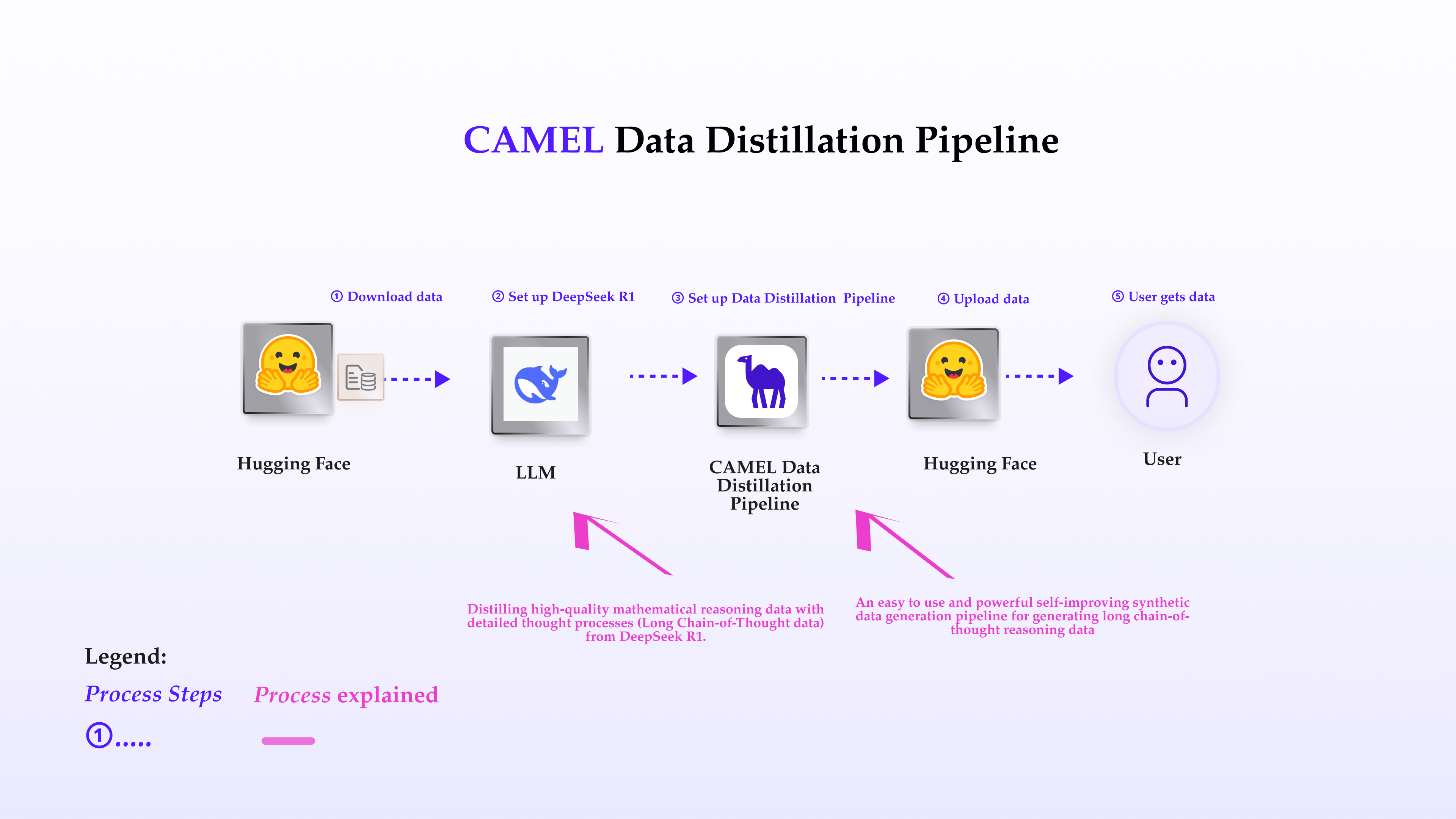
This notebook provides a comprehensive guide on configuring and utilizing CAMEL’s data distillation pipeline to generate high-quality mathematical reasoning datasets featuring detailed thought processes (Long Chain-of-Thought data). In this notebook, you’ll explore:
- CAMEL: A powerful multi-agent framework that enables synthetic data generation and multi-agent role-playing scenarios, enabling advanced AI-driven applications.
- Data distillation pipeline: A systematic approach for extracting and refining high-quality reasoning datasets with detailed thought processes from models like DeepSeek R1.
- Hugging Face Integration: A streamlined process for uploading and sharing distilled datasets on the Hugging Face platform.
- 📚 AMC AIME STaR Dataset A dataset of 4K advanced mathematical problems and solutions, distilled with improvement history showing how the solution was iteratively refined. 🔗 Explore the Dataset
- 📚 AMC AIME Distilled Dataset A dataset of 4K advanced mathematical problems and solutions, distilled with clear step-by-step solutions. 🔗 Explore the Dataset
- 📚 GSM8K Distilled Dataset A dataset of 7K high quality linguistically diverse grade school math word problems and solutions, distilled with clear step-by-step solutions. 🔗 Explore the Dataset
📦 Installation
Firstly, we need to install the camel-ai package for datagen pipeline🔑 Setting Up API Keys
Let’s set theFIREWORKS_API_KEY or DEEPSEEK_API_KEY that will be used to distill the maths reasoning data with thought process.
⭐ NOTE: You could also use other model provider like Together AI, SilionFlow
📥 Download Dataset from Hugging Face and Convert to the Desired Format
Now, lets start to prepare the original maths data from Hugging Face ,which mainly have two important key: questions and answers. We will use GSM8K as example. After we download these datasets, we will convert these datasets to the desired format which suitable to be used in CAMEL’s data distillation pipeline.🚀 Begin Distilling Mathematical Reasoning Data with Thought Process (Long CoT Data).
Import required libraries:📤 Upload the Data to Hugging Face
After we’ve distilled the desired data, let’s upload it to Hugging Face and share it with more people! Define the dataset upload pipeline, including steps like creating records, generating a dataset card, and other necessary tasks.🔑 Config Access Token of Hugging Face and Upload the Data
You can go to here to get API Key from Hugging Face, also make sure you have opened the write access to repository.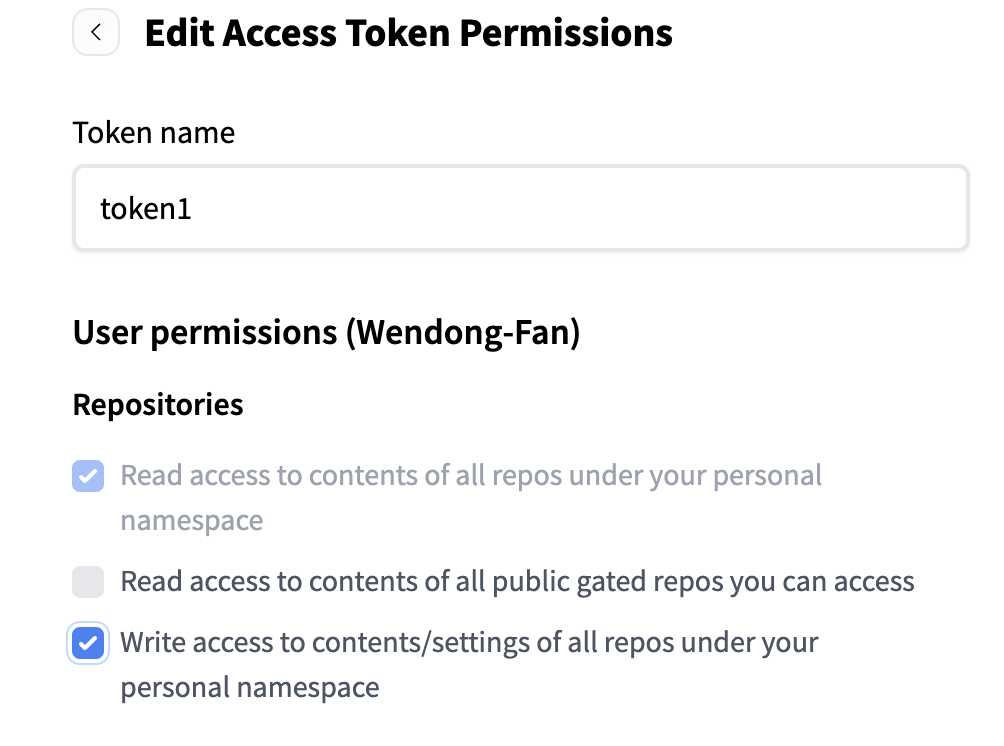
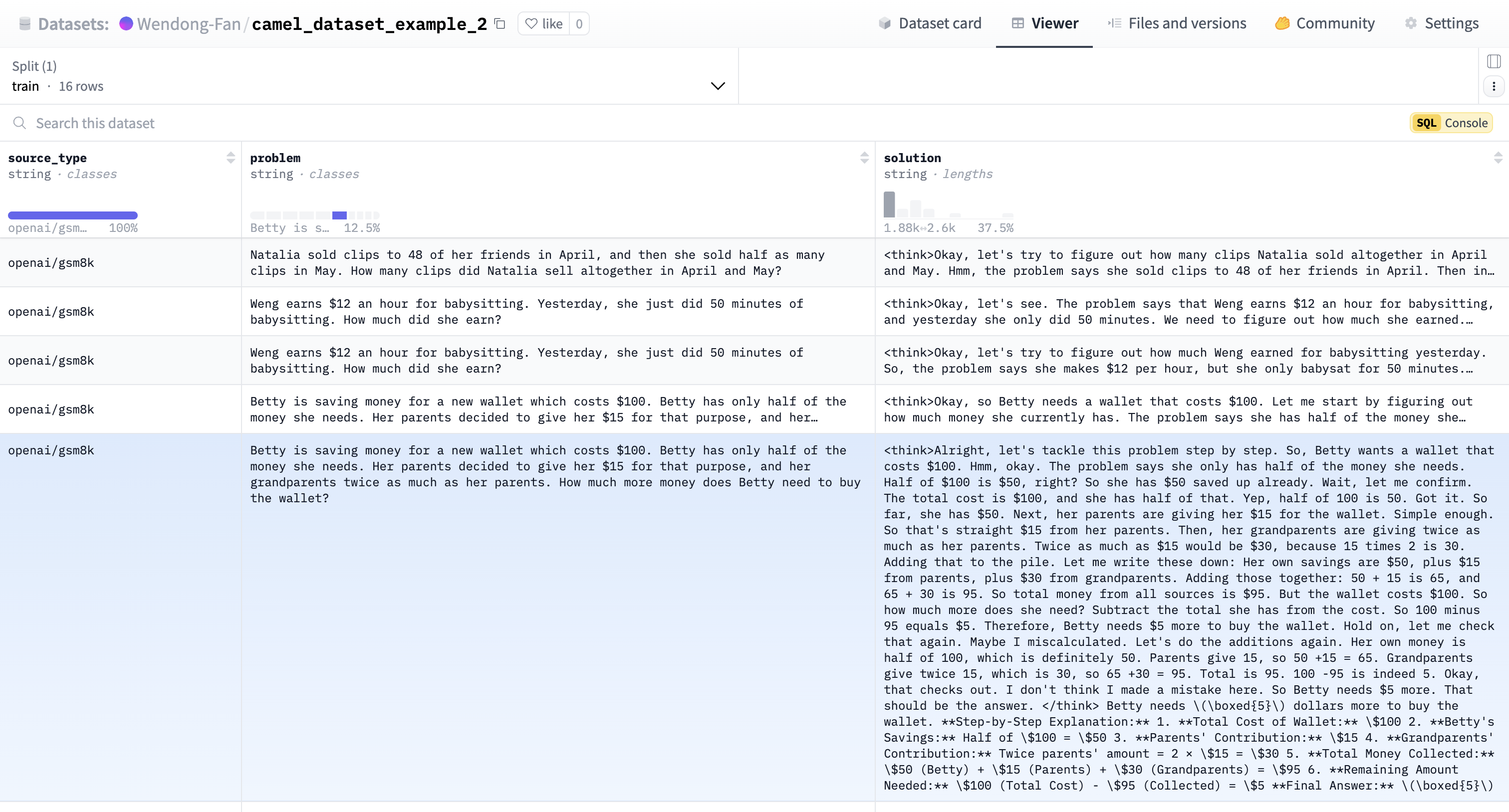
📊 Final Uploaded Data Preview
🌟 Highlights
- High-Quality Synthetic Data Generation: CAMEL’s pipeline distills mathematical reasoning datasets with detailed step-by-step solutions, ideal for synthetic data generation.
- Public Datasets: Includes the AMC AIME STaR, AMC AIME Distilled, and GSM8K Distilled Datasets, providing diverse problems and reasoning solutions across various math topics.
- Hugging Face Integration: Easily share and access datasets on Hugging Face for collaborative research and development.
- Customizable & Scalable: Supports parallel processing, customizable agents, and reward models for efficient, large-scale data generation.
- 🐫 Creating Your First CAMEL Agent free Colab
- Graph RAG Cookbook free Colab
- 🧑⚖️ Create A Hackathon Judge Committee with Workforce free Colab
- 🔥 3 ways to ingest data from websites with Firecrawl & CAMEL free Colab
- 🦥 Agentic SFT Data Generation with CAMEL and Mistral Models, Fine-Tuned with Unsloth free Colab