

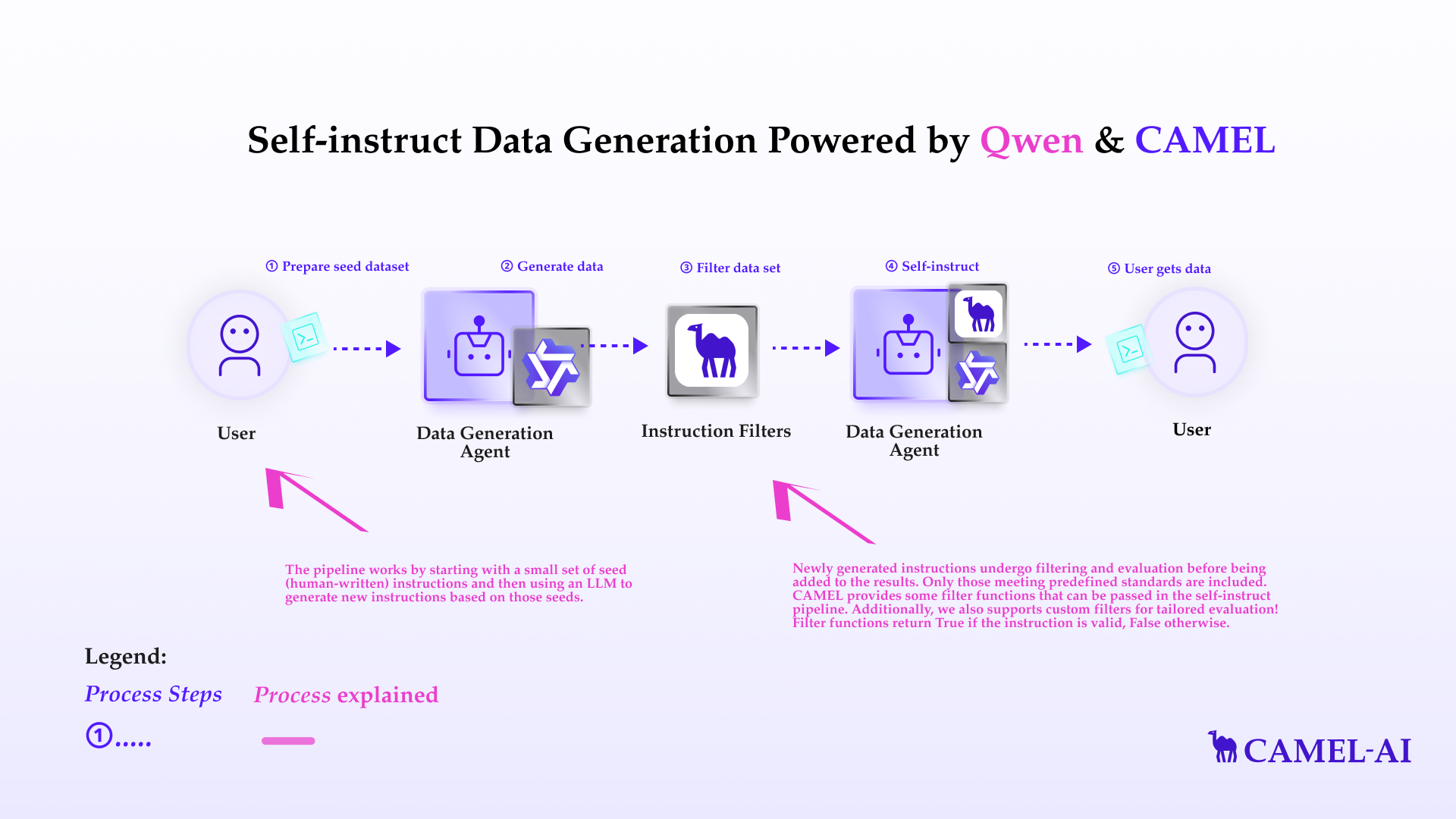
The self-instruct pipeline is a technique for automatically generating instructions for large language models (LLMs). Manually creating these datasets can be time-consuming and expensive. The self-instruct pipeline provides a way to automate this process and generate large numbers of instructions quickly and efficiently. In this notebook, you’ll explore:
- CAMEL-AI: A versatile multi-agent framework that facilitates the creation and execution of complex data tasks.
- Qwen: A large language model by Alibaba Cloud, used for instruction generation.
- Self-Instruct Pipeline: A technique for automating instruction dataset creation.
- Instruction Filters: A set of filters that is used to filter a dataset.
Installation and Setup
First, install the CAMEL package with all its dependenciesBasic Agent Setup
Basic Pipeline Setup
The pipeline works by starting with a small set of seed (human-written) instructions and then using an LLM to generate new instructions based on those seeds.- The seed instructions are typically stored in a JSON Lines (JSONL) file. Each line in the file represents a single instruction in JSON format.
- Like the seed file, the output is also stored in JSONL format, making it easy to parse and use for further tasks, such as training or fine-tuning language models.
seed_path with the path to your seed file, and replace data_output_path with your desired output location.
- It selects a certain number of human-written instructions (
num_human_sample) from theseed_path. - It selects a certain number of machine-generated instructions (
num_machine_sample) from previous rounds. - It uses these selected instructions to guide the language model in generating new instructions.
- These new instructions are added to the pool of machine-generated instructions, and the process repeats until the desired number of instructions is generated.
human_to_machine_ratio helps control the balance between human guidance and the model’s creativity throughout this process. By adjusting this ratio, you can influence the quality and diversity of the generated instructions.
Feel free to alter num_human_sample and num_machine_sample, which both will be passed into human_to_machine_ratio later
target_num_instructions with the number of machine instructions you want to generate
Filter functions
Newly generated instructions undergo filtering and evaluation before being added to the results. Only those meeting predefined standards are included. CAMEL provides some filter functions that can be passed in the self-instruct pipeline. Additionally, we also supports custom filters for tailored evaluation! Filter functions returnTrue if the instruction is valid, False otherwise.
Length Filter
LengthFilter filters out all the instructions which has a length less than min_len or greater than max_len.
Keyword Filter
KeywordFilter filters instructions that contain specific undesirable keyword.
Punctuation Filter
PunctuationFilter filters instructions that begin with a non-alphanumeric character.
Non-English Filter
NonEnglishFilter filters instructions that do not begin with English letters.
ROUGE Similarity Filter
RougeSimilarityFilter filters instructions that are too similar to existing instructions based on ROUGE scores.
Custom Filter Function
Additionally, you could implement your own filter function.Instruction Filter
InstructionFilter manages all filter functions. And we can use a custom InstructionFilter to initialize the pipeline
Start by adding filter functions you want and configure them.
InstructionFilter
Pipeline Setup with Custom InstructionFilter
CAMEL has some default filter functions inside the pipeline, but you can also choose your own!
- 🐫 Creating Your First CAMEL Agent free Colab
- Graph RAG Cookbook free Colab
- 🧑⚖️ Create A Hackathon Judge Committee with Workforce free Colab
- 🔥 3 ways to ingest data from websites with Firecrawl & CAMEL free Colab
- 🦥 Agentic SFT Data Generation with CAMEL and Mistral Models, Fine-Tuned with Unsloth free Colab