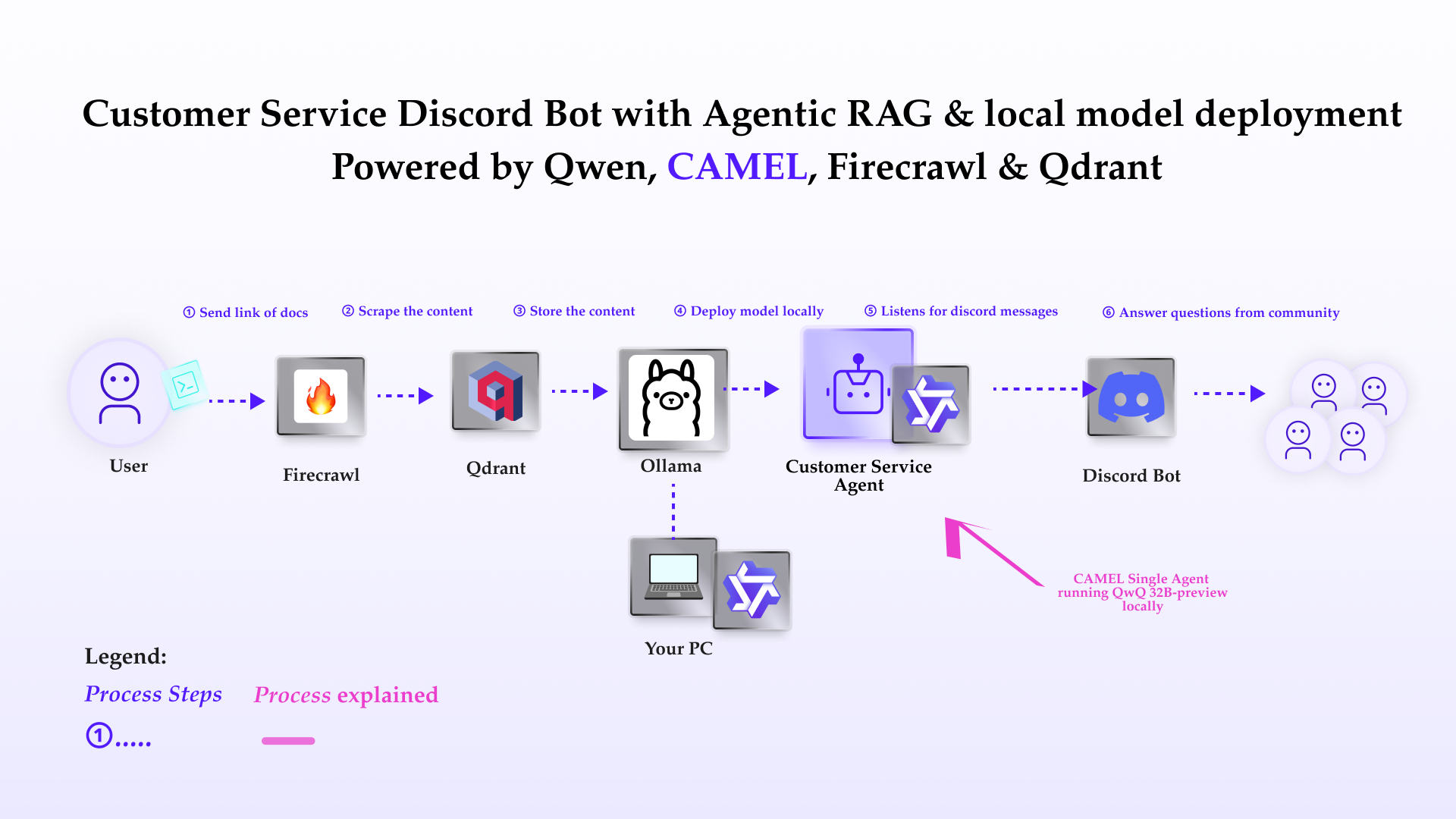
- CAMEL: An open-source toolkit for building and deploying large language model (LLM) applications.
- Firecrawl: A tool for web scraping and creating a local knowledge base.
- Qdrant: A vector database for efficient knowledge retrieval.
- Ollama: A local model deployment for running the LLM without external dependencies.


Installation and Setup
First, install the CAMEL package with all its dependenciesLocal setup
Please make a copy of this notebook (important), or run this notebook locally. If you choose to make a copy of this notebook and stay in Google colab, connect the copied notebook to your local runtime by follow the following steps:- Install notebook locally by running the following command in your terminal:
- Copy any of the url, and click on ‘connect to a local runtime’ button in Google Colab, and paste the copied url into Backend Url.
- Click on ‘connect’
Basic Agent and local model Setup
- Download Ollama for a local model at: https://ollama.com/download
- After setting up Ollama, pull the Llama3 model by typing the following command into the terminal:
- Create a script to get the base model (llama3) and create a custom model using the
ModelFileabove. Save this as a .sh file: (Optional)
Knowledge Crawling and Storage
Use Firecrawl to crawl a website and store the content in a markdown file:Basic Chatbot Setup
Basic Discord Bot Integration
To build a discord bot, a discord bot token is necessary. If you don’t have a bot token, you can obtain one by following these steps:- Go to the Discord Developer Portal:https://discord.com/developers/applications
- Log in with your Discord account, or create an account if you don’t have one
- Click on ‘New Application’ to create a new bot.
- Give your application a name and click ‘Create’.
- Navigate to the ‘Bot’ tab on the left sidebar and click ‘Add Bot’.
- Once the bot is created, you will find a ‘Token’ section. Click ‘Reset Token’ to generate a new token.
- Copy the generated token securely.
- Navigate to the ‘OAuth2’ tab, then to ‘URL Generator’.
- Under ‘Scopes’, select ‘bot’.
- Under ‘Bot Permissions’, select the permissions your bot will need (e.g., ‘Send Messages’, ‘Read Messages’ for our bot use)
- Copy the generated URL and paste it into your browser to invite the bot to your server.
- Navigate to the ‘Bot’ tab
- Under ‘Privileged Gateway Intents’, check ‘Server Members Intent’ and ‘Message Content Intent’.
Integrating Qdrant for Large Files to build a more powerful Discord bot
Qdrant is a vector similarity search engine and vector database. It is designed to perform fast and efficient similarity searches on large datasets of vectors. This enables the chatbot to access and utilize external information to provide more comprehensive and accurate responses. By storing knowledge as vectors, Qdrant enables efficient semantic search, allowing the chatbot to find relevant information based on the meaning of the user’s query. Set up an embedding model and retriever for Qdrant: feel free switch to other embedding models supported by CAMEL. Set up an embedding model and retriever for Qdrant:ChatAgent based on the retrieved info:
If you are connecting this cookbook to a local runtime, adding files in your local path in contents might cause an error.

- 🐫 Creating Your First CAMEL Agent free Colab
- Graph RAG Cookbook free Colab
- 🧑⚖️ Create A Hackathon Judge Committee with Workforce free Colab
- 🔥 3 ways to ingest data from websites with Firecrawl & CAMEL free Colab
- 🦥 Agentic SFT Data Generation with CAMEL and Mistral Models, Fine-Tuned with Unsloth free Colab