- CAMEL: A powerful multi-agent framework that enables Retrieval-Augmented Generation and multi-agent role-playing scenarios, allowing for sophisticated AI-driven tasks.
- Mistral: Utilized for its state-of-the-art language models, which enable tool-calling capabilities to execute external functions, while its powerful embeddings are employed for semantic search and content retrieval.
- Firecrawl: A robust web scraping tool that simplifies extracting and cleaning content from various web pages.
- AgentOps: Track and analysis the running of CAMEL Agents.
- Qdrant: An efficient vector storage system used with CAMEL’s AutoRetriever to store and retrieve relevant information based on vector similarities.
- Neo4j: A leading graph database management system used for constructing and storing knowledge graphs, enabling complex relationships between entities to be mapped and queried efficiently.
- DuckDuckGo Search: Utilized within the SearchToolkit to gather relevant URLs and information from the web, serving as the primary search engine for retrieving initial content.
- Unstructured IO: Used for content chunking, facilitating the management of unstructured data for more efficient processing.
📦 Installation
First, install the CAMEL package with all its dependencies:🔑 Setting Up API Keys
You’ll need to set up your API keys for Mistral AI, Firecrawl and AgentOps. This ensures that the tools can interact with external services securely. You can go to here to get free API Key from AgentOps🌐 Web Scraping with Firecrawl
Firecrawl is a powerful tool that simplifies web scraping and cleaning content from web pages. In this section, we will scrape content from a specific post on the CAMEL AI website as an example.🛠️ Web Information Retrieval using CAMEL’s RAG and Firecrawl
In this section, we’ll demonstrate how to retrieve relevant information from a list of URLs using CAMEL’s RAG model. This is particularly useful for aggregating and analyzing data from multiple sources.Setting Up Firecrawl with CAMEL’s RAG
The following function retrieves relevant information from a list of URLs based on a given query. It combines web scraping with Firecrawl and CAMEL’s AutoRetriever for a seamless information retrieval process.📹 Monitoring AI Agents with AgentOps
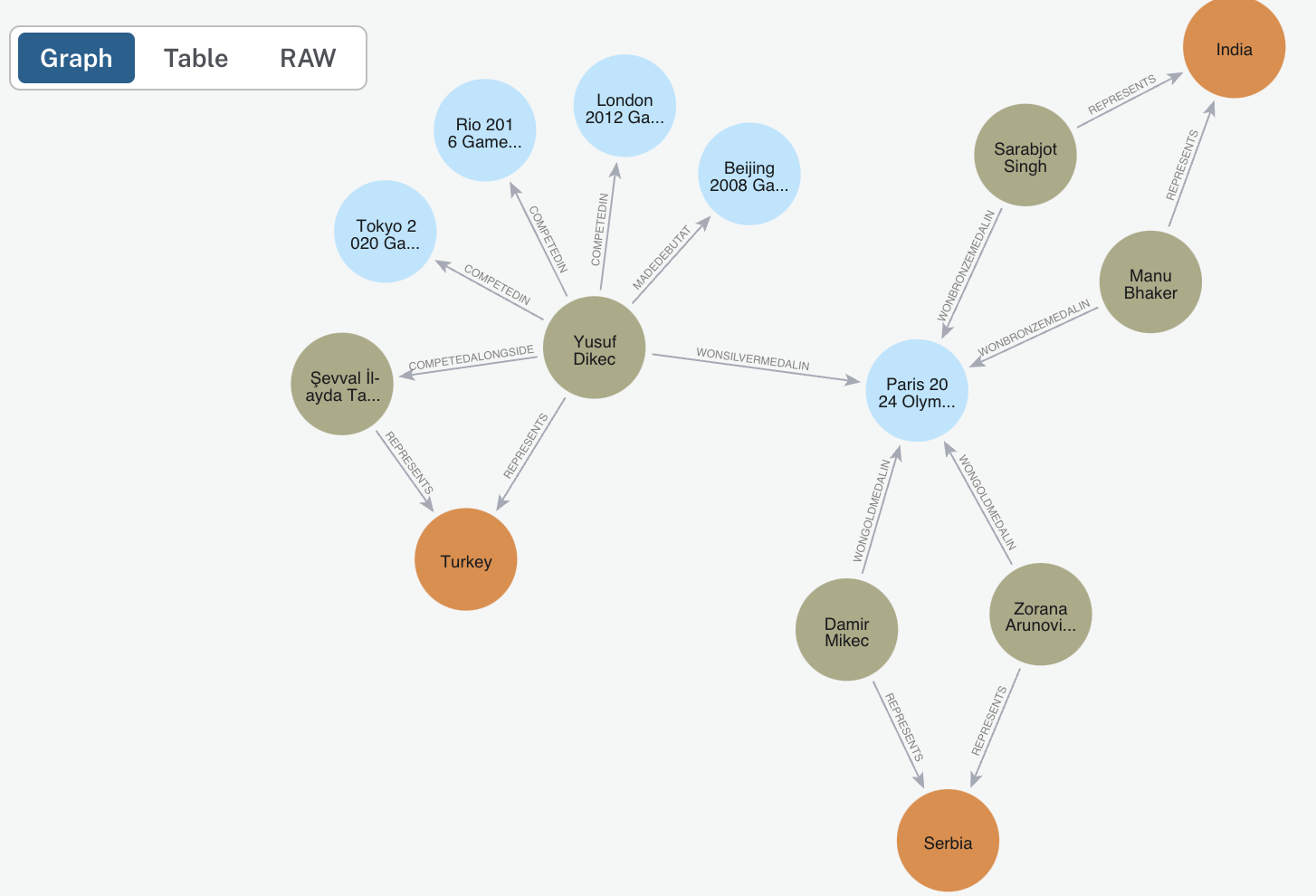
🧠 Knowledge Graph Construction
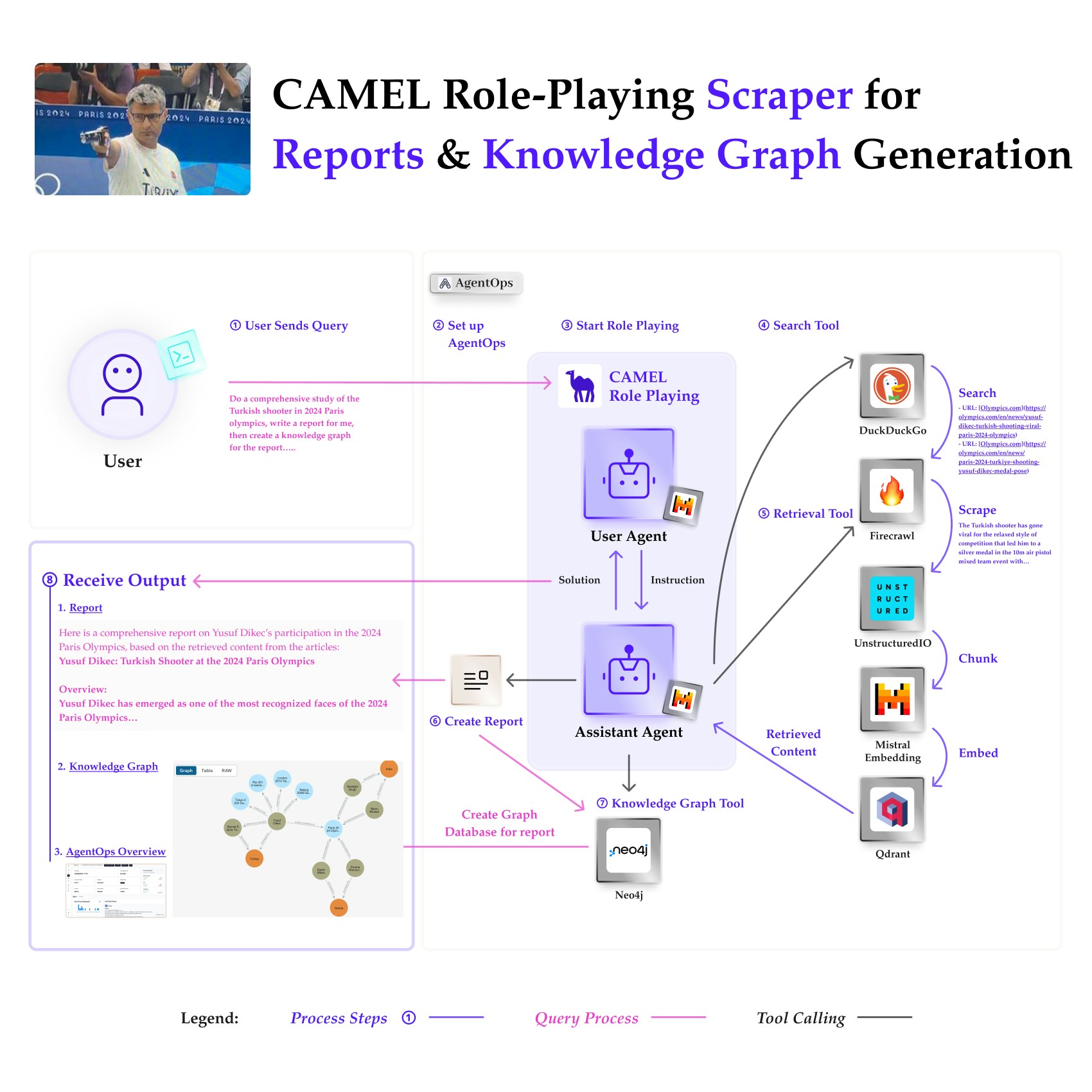
A powerful feature of CAMEL is its ability to build and store knowledge graphs from text data. This allows for advanced analysis and visualization of relationships within the data. Set up your Neo4j instance by providing the URL, username, and password, here is the guidance, check your credentials in the downloaded .txt file. Note that you may need to wait up to 60 seconds if the instance has just been set up.🤖🤖 Multi-Agent Role-Playing with CAMEL
This section sets up a role-playing session where AI agents interact to accomplish a task using various tools. We will guide the assistant agent to perform a comprehensive study of the Turkish shooter in the 2024 Paris Olympics.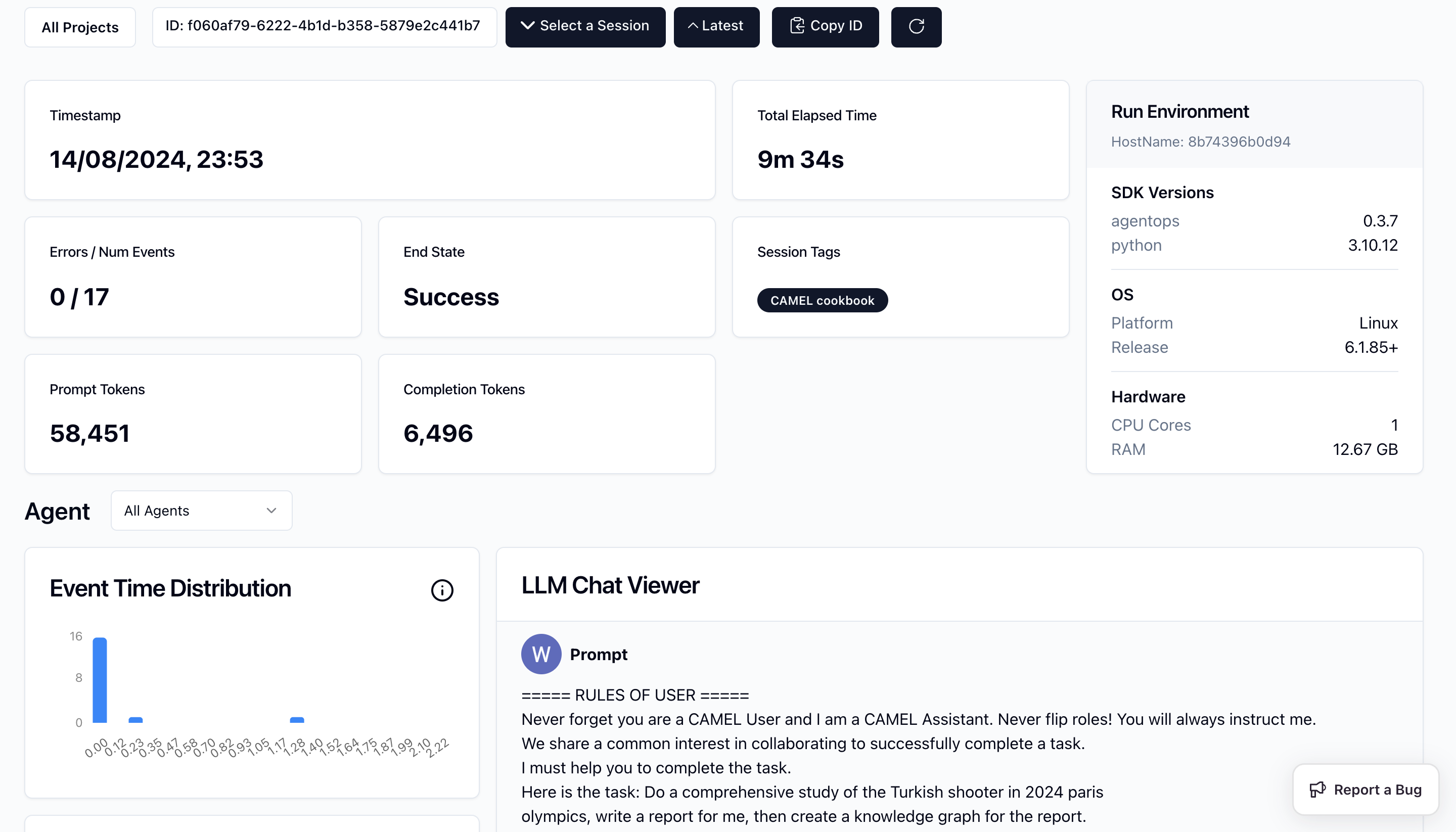
🌟 Highlights
This notebook has guided you through setting up and running a CAMEL RAG workflow with Firecrawl for a complex, multi-agent role-playing task. You can adapt and expand this example for various other scenarios requiring advanced web information retrieval and AI collaboration. Key tools utilized in this notebook include:- CAMEL: A powerful multi-agent framework that enables Retrieval-Augmented Generation and multi-agent role-playing scenarios, allowing for sophisticated AI-driven tasks.
- Mistral: Utilized for its state-of-the-art language models, which enable tool-calling capabilities to execute external functions, while its powerful embeddings are employed for semantic search and content retrieval.
- Firecrawl: A robust web scraping tool that simplifies extracting and cleaning content from various web pages.
- AgentOps: Track and analysis the running of CAMEL Agents.
- Qdrant: An efficient vector storage system used with CAMEL’s AutoRetriever to store and retrieve relevant information based on vector similarities.
- Neo4j: A leading graph database management system used for constructing and storing knowledge graphs, enabling complex relationships between entities to be mapped and queried efficiently.
- DuckDuckGo Search: Utilized within the SearchToolkit to gather relevant URLs and information from the web, serving as the primary search engine for retrieving initial content.
- Unstructured IO: Used for content chunking, facilitating the management of unstructured data for more efficient processing.