

This notebook demonstrates how to build a dynamic knowledge graph using CAMEL’s Knowledge Graph Agent and Neo4j. The knowledge graph is constructed by parsing PDF documents, extracting entities and relationships, and storing them in a Neo4j database. The graph is then queried to retrieve time-based relationships. In this notebook, you’ll explore:
- CAMEL: A powerful multi-agent framework that enables the construction of knowledge graphs from unstructured data.
- Neo4j: A graph database used to store and query the knowledge graph.
- Together and SambaVerse Models: Large language models used to generate the knowledge graph from parsed documents.
- Deduplication: Techniques to ensure the uniqueness of nodes and relationships in the graph.
📦 Installation
First, install the CAMEL package with all its dependencies: Second, make sure that Neo4j is running and accessible from your local machine.🚀 Launch Service
Start Neo4j service in the background((using Ubuntu as an example))🔑 Setting Up API Keys
You’ll need to set up your API keys for Together and SambaVerse. This ensures that the tools can interact with external services securely.🛠️ Setting Up Neo4j
To store and query the knowledge graph, you’ll need a Neo4j instance. If you don’t have one, you can set up a local instance or use a cloud service like Neo4j Aura.- Local Setup: Download and install Neo4j Desktop from here.
- Cloud Setup: Sign up for Neo4j Aura here.
🧠 Setting Up the Knowledge Graph Agent
We will use CAMEL’s Knowledge Graph Agent to parse PDF documents, extract entities and relationships, and store them in the Neo4j database. The agent uses Together and SambaVerse models for graph generation. Replace the file path in the code below with your own data directory path example_file_dir = Path(“/home/mi/daily/fin-camel/pdf_tmp”)🏗️ Building the Knowledge Graph
The ID normalization process ensures compliant Neo4j identifiers by sanitizing input strings (replacing non-alphanumeric characters with underscores), ensuring no numeric prefixes, splitting/cleaning components, and applying SHA-1 hashing truncation to enforce a maximum 64-character limit while preserving uniqueness and readability.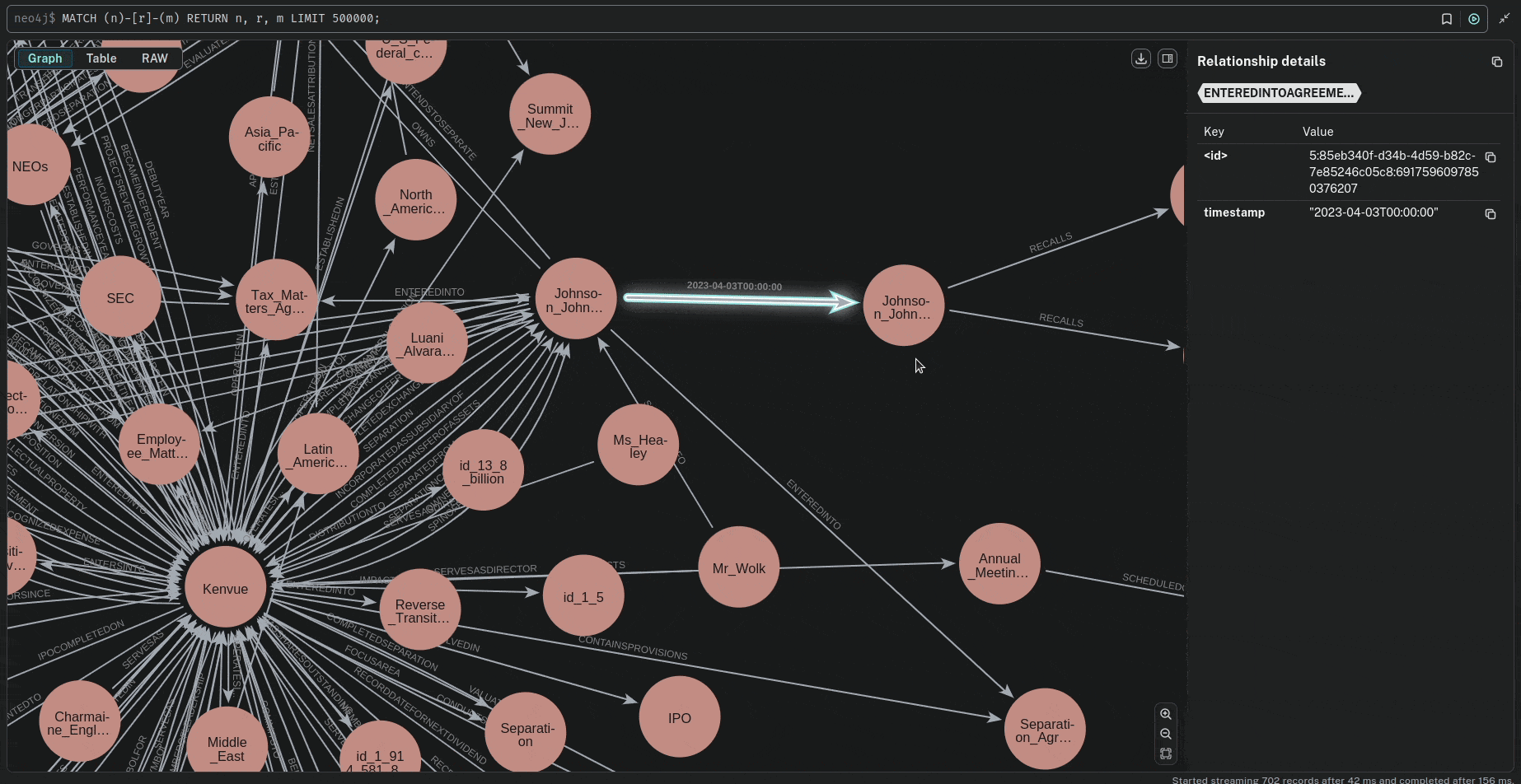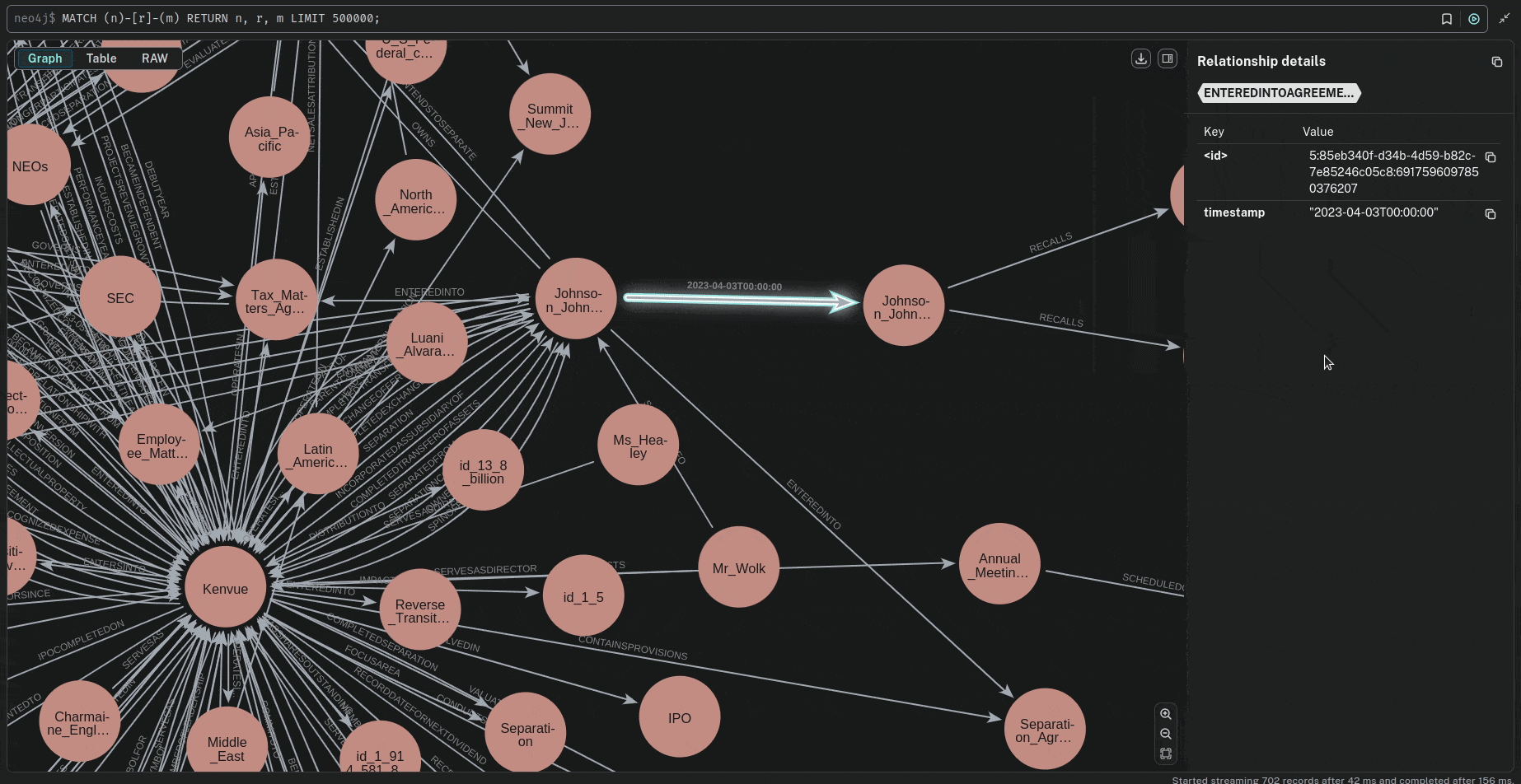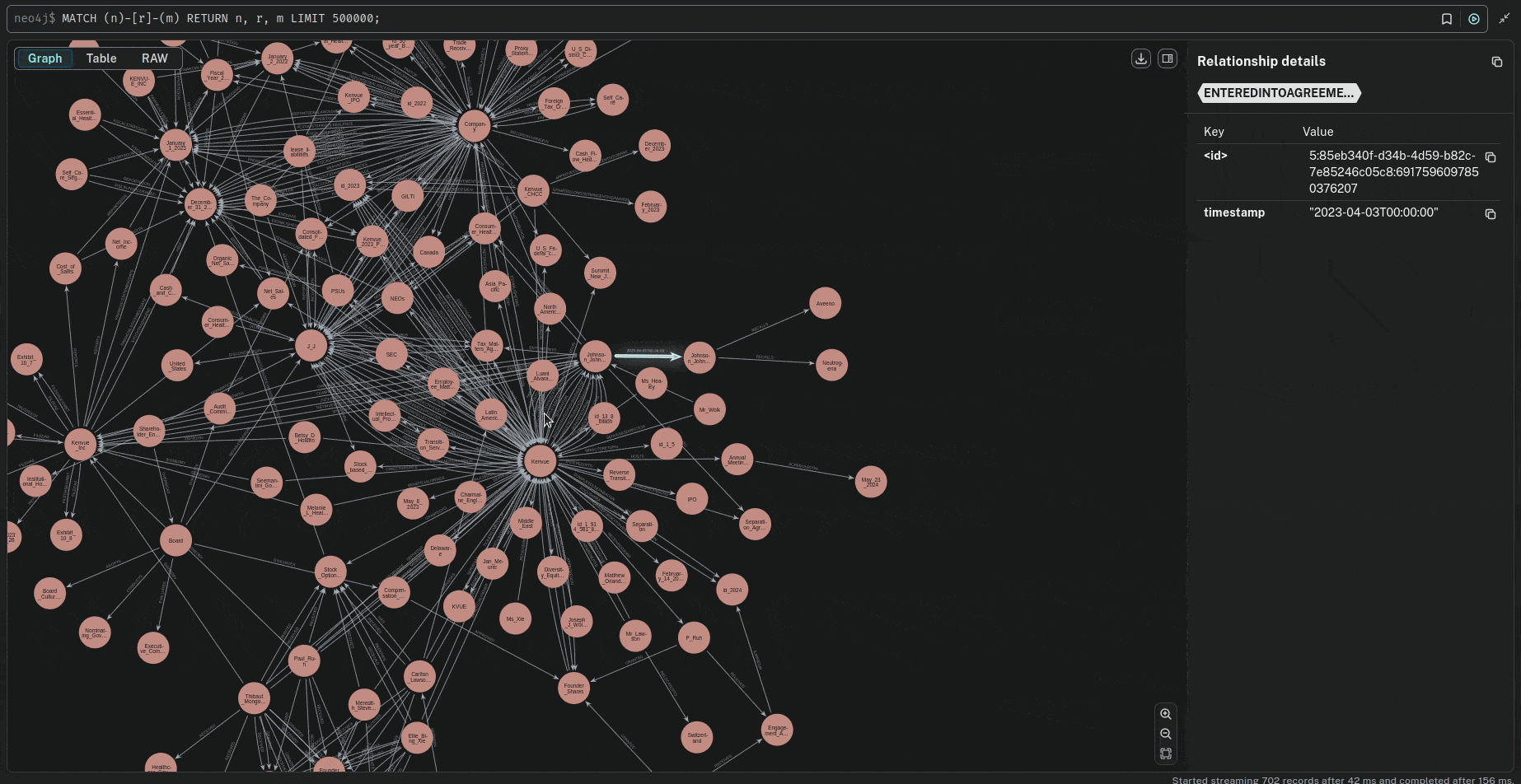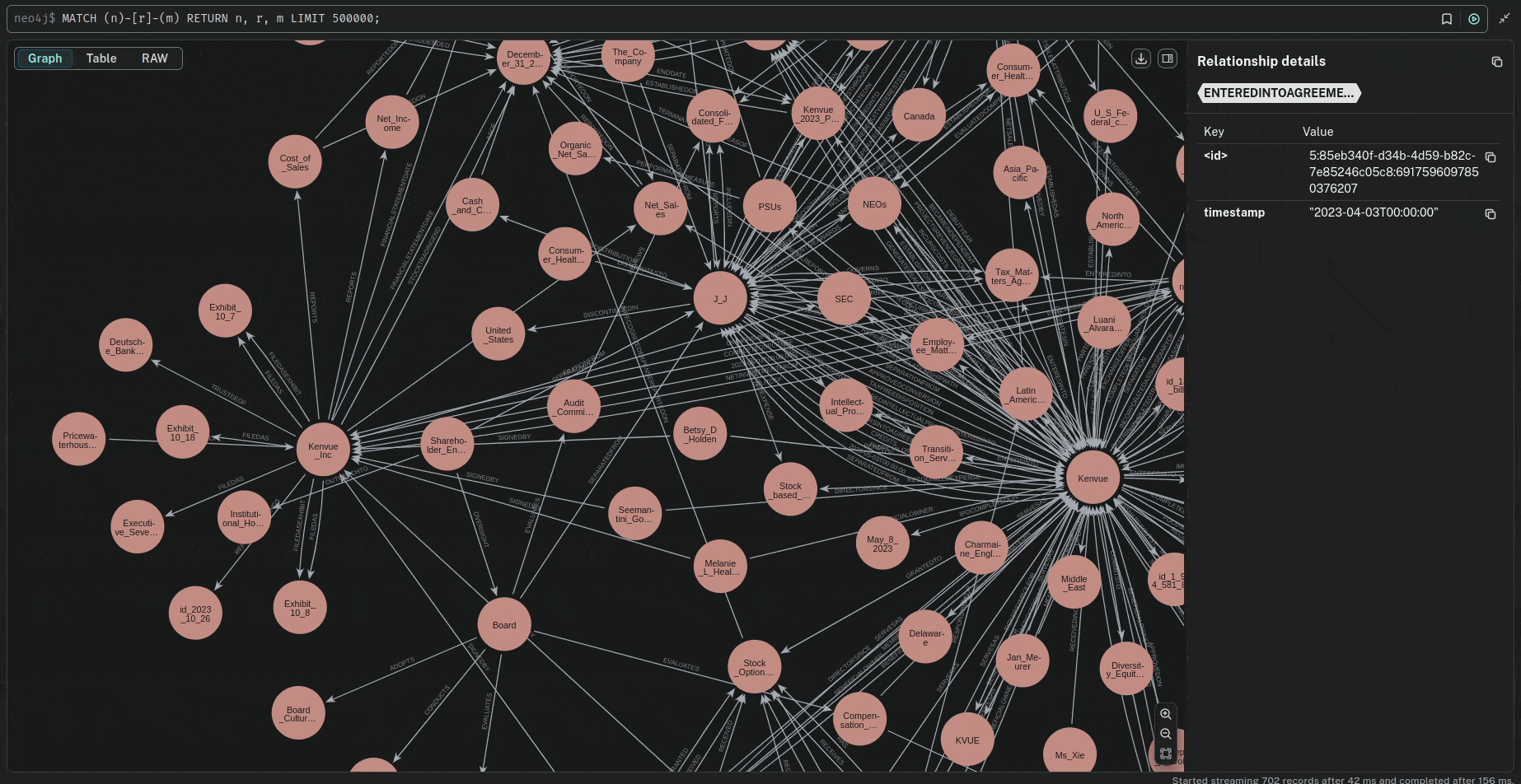
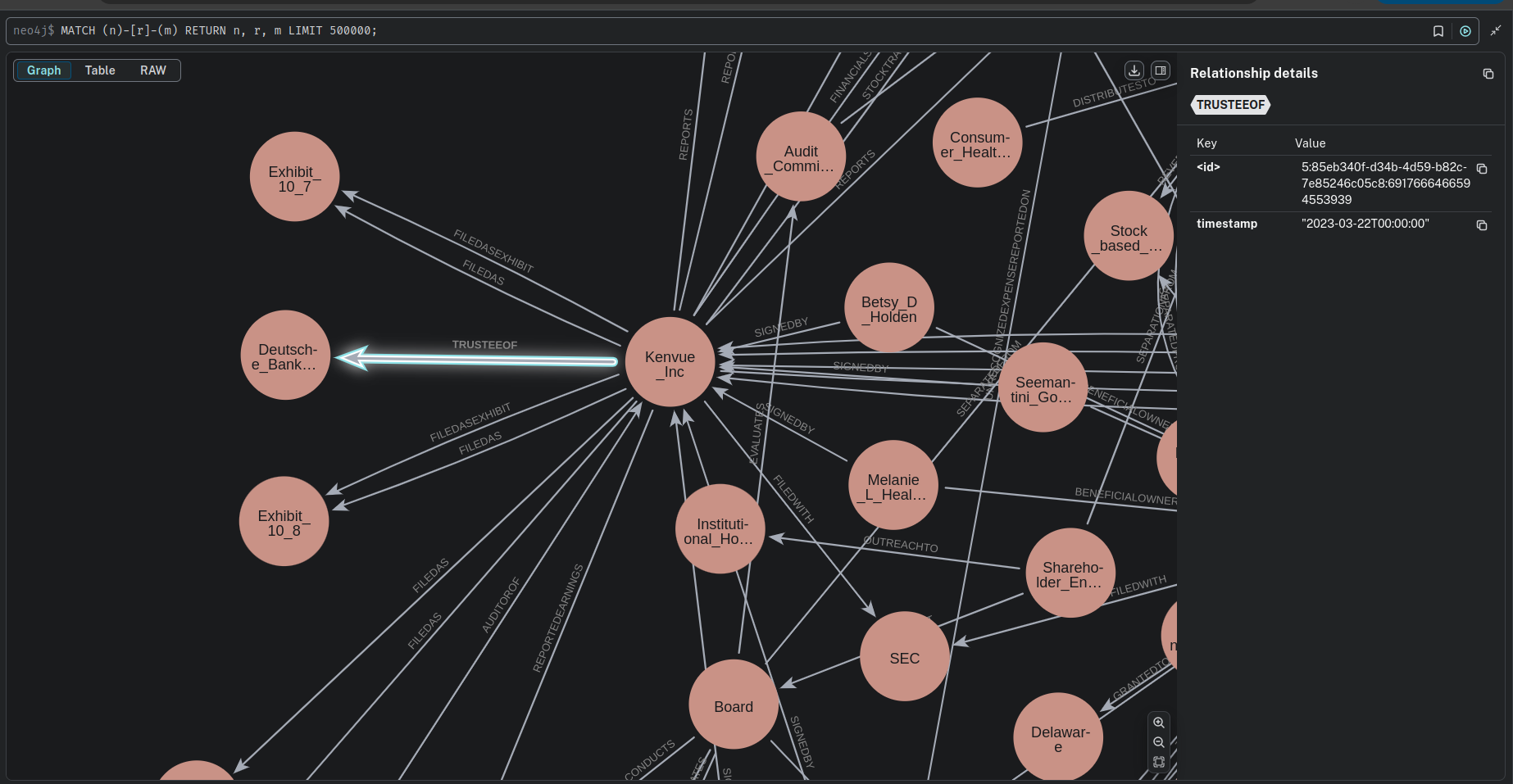
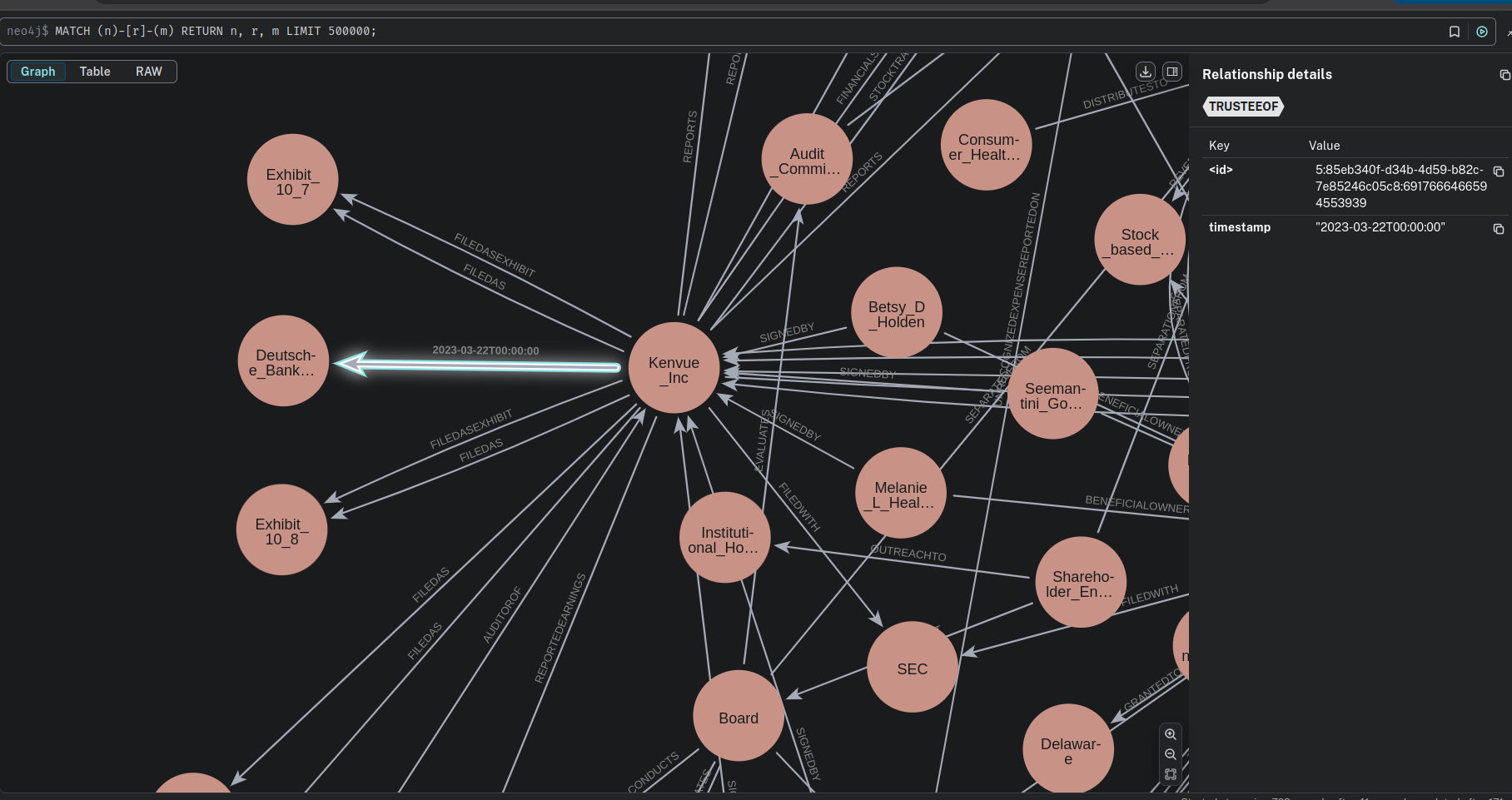
🔍 Querying the Knowledge Graph
Now that the knowledge graph is built, we can query it to retrieve time-based relationships.Parameters Investigation.
max_characters: The maximum number of characters in a chunk.model: The model to use for the knowledge graph agent. (TogetherAI or Samba Verse)
🌟 Highlights
This notebook has guided you through setting up and running a dynamic knowledge graph construction workflow using CAMEL’s Knowledge Graph Agent and Neo4j. You can adapt and expand this example for various other scenarios requiring dynamic graph generation and querying. Key tools utilized in this notebook include:- CAMEL: A powerful multi-agent framework that enables the construction of knowledge graphs from unstructured data.
- Neo4j: A graph database used to store and query the knowledge graph.
- Together and SambaVerse Models: Large language models used to generate the knowledge graph from parsed documents.
- Deduplication: Techniques to ensure the uniqueness of nodes and relationships in the graph.